by Li Ye1 , Xinhang Zhou1 , Xingyu Yang1 , Peng Fan1 , Ruofeng Tong1 , Hailong Li2 , Peng Du1 , and Min Tang1, *
1 - Zhejiang University, Hangzhou, 310007, China
2 - Shenzhen Poisson Software Co., Ltd., Shenzhen, 518129, China
* - Corresponding Author
Abstract
Mid-surface abstraction is essential for finite element analysis of thin-walled CAD models, yet existing face pairing-based methods
suffer from quadratic complexity and CPU-bound bottlenecks, limiting scalability for variable-thickness models. We present
gMidSurf, a GPU-accelerated pipeline that transforms the two computational bottlenecks in mid-surface abstraction (face pairing
and mid-point generation) into massively parallel operations. For face pairing, we introduce a hierarchical filtering strategy that
progressively culls candidate pairs through three GPU-optimized gates: normal compatibility, simplified overlap criterion, and
LBVH-based distance queries, reducing the search space by 10–100× while maintaining cache coherence. For mid-point
generation, we employ parallel distance dilation followed by bracket-and-bisect refinement for precise equidistant point localization.
This method handles variable-thickness models with complex surfaces through complete dilation, thereby avoiding gaps and truncations
that occur in previous methods. Experimental results on real-world benchmarks demonstrate that gMidSurf achieves 4.2×–18.5×
speedups in face pairing and 4.8×–9.8× in mid-point generation compared to CPU implementations, yielding 5×–15× acceleration
on a commodity GPU (NVIDIA RTX 5090D) compared to state-of-the-art methods while maintaining geometric accuracy.

Overview: The input thin-walled model is first discretized into triangular meshes on the GPU. Then (a) hierarchical GPU-based face pairing applies three progressive filtering gates (normal, overlap, and distance) to prune candidate face pairs by 10–100× and identify the face group pairs (FGPs), abstracting 1-1 face pairs into n-n FGPs through parallel bipartite graph optimization. Next, (b) GPU-based mid-point generation produces initial mid-points via parallel distance dilation and refines them to precise equidistant points through a bracket-and-bisect kernel. Finally, the model undergoes surface fitting and trimming operations to determine the boundaries of the mid-surface, yielding the final output mid-surface.
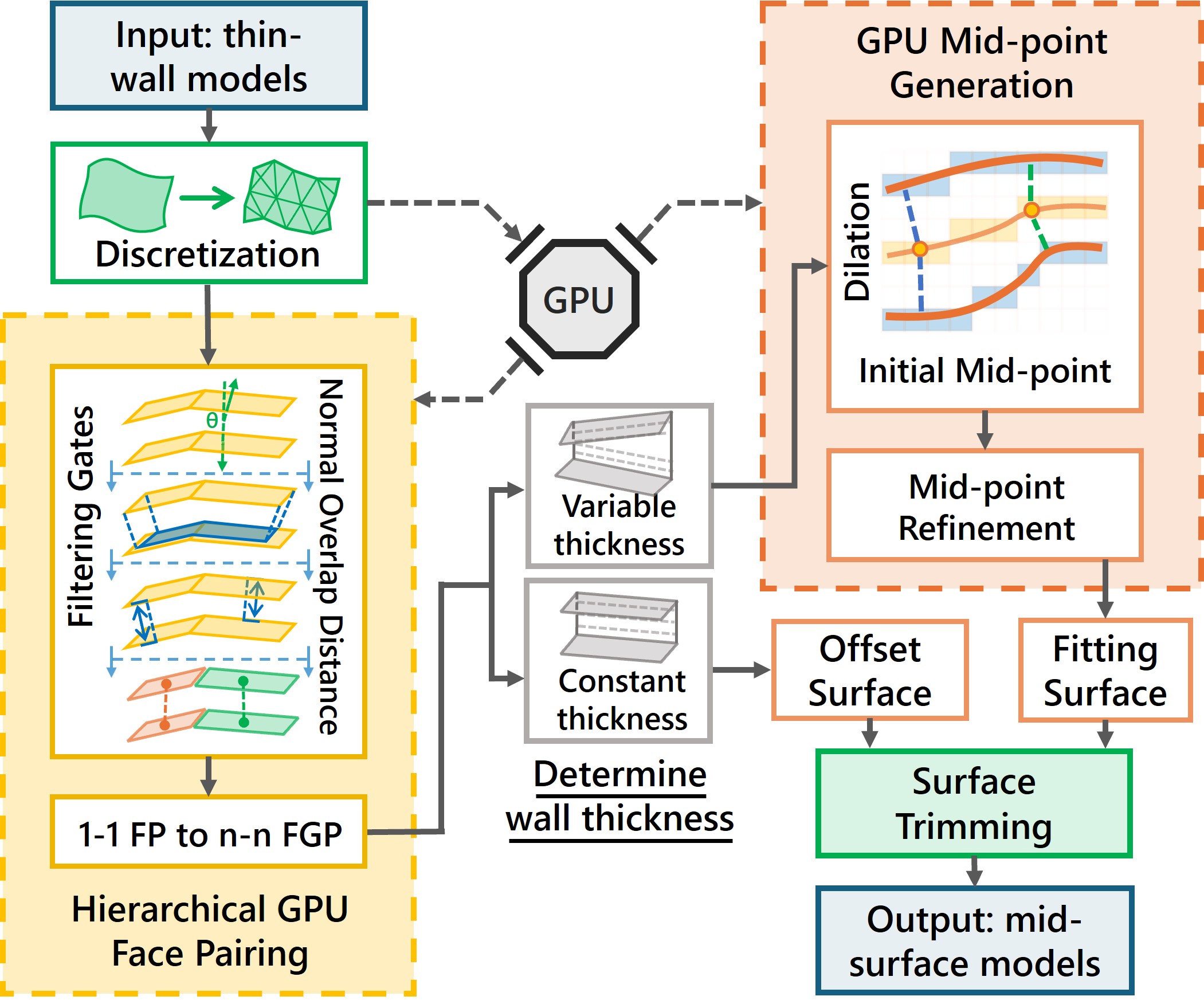
Pipeline: The gMidSurf pipeline keeps geometry resident on the GPU through both core stages. Two computational bottlenecks — hierarchical GPU-based face pairing and dilation-based precise mid-point generation — are recast as massively parallel operations, while surface fitting and trimming run on the host. This end-to-end design preserves B-Rep modeling intent, supports both 1-1 and n-n face pairs, and handles constant- and variable-thickness regions robustly.
Technical Contributions
Key Results
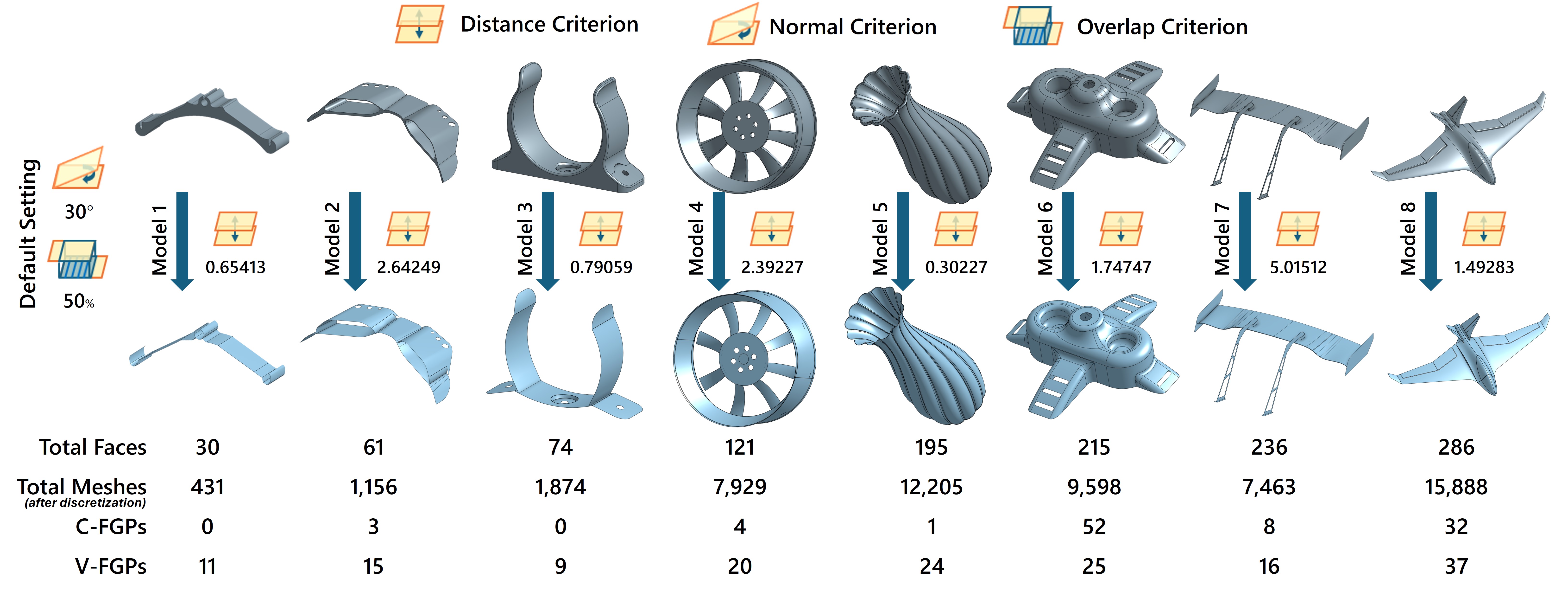
Benchmark:
Eight iconic models (M1–M8) selected from the GrabCAD library cover a diverse range of geometric and topological configurations,
including constant- and variable-thickness FGPs (C/V-FGPs), high curvature, n-n pairings, and complex free-form surfaces.